| sample | feature_1 | feature_2 |
|---|---|---|
| control | 10000 | 1000 |
| treatment | 11000 | 2000 |
Analysis of metabolomics data
Data pre-treatment
Different types of data centering, scaling, and transformation, from van den Berg et al., Genomics 2006
Centering
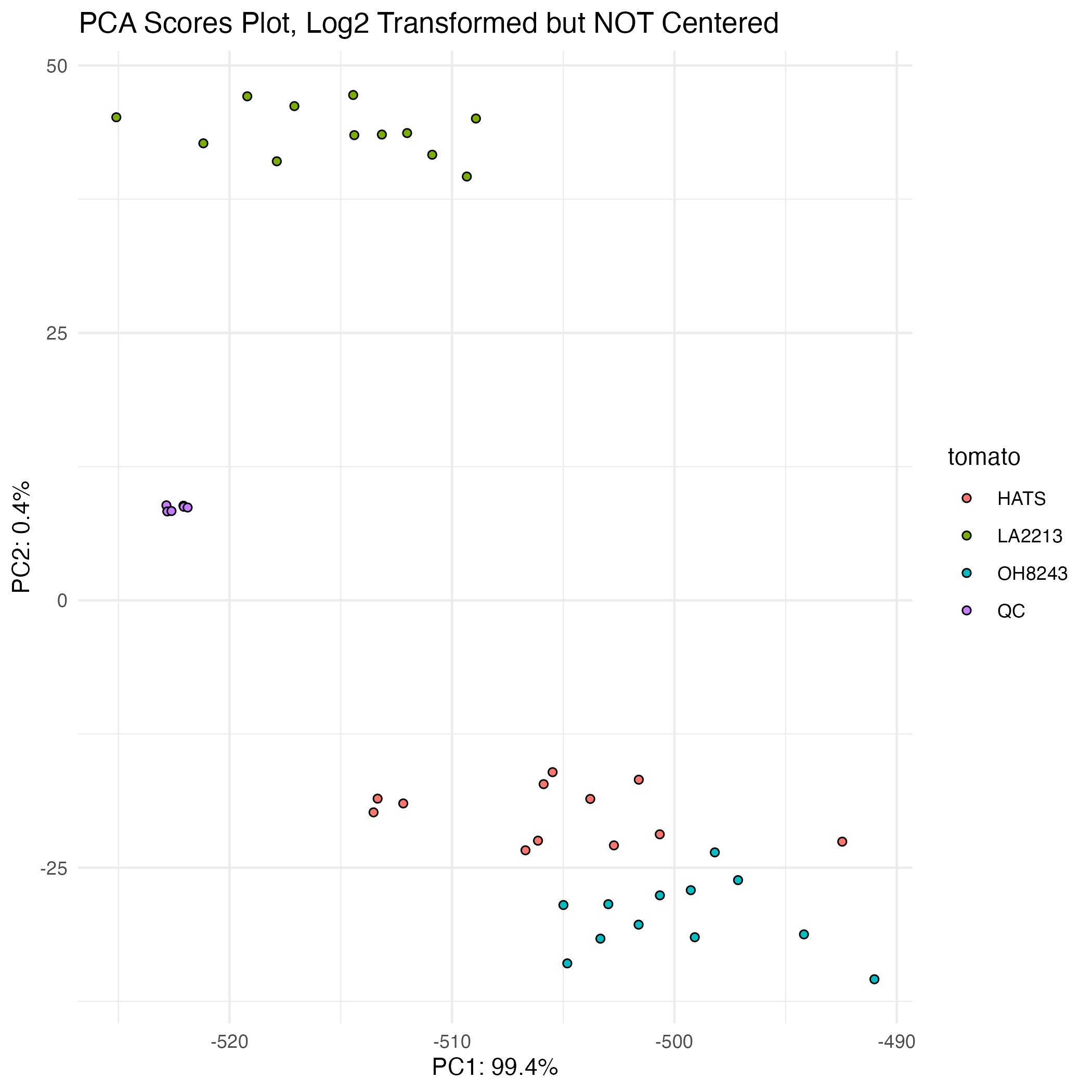
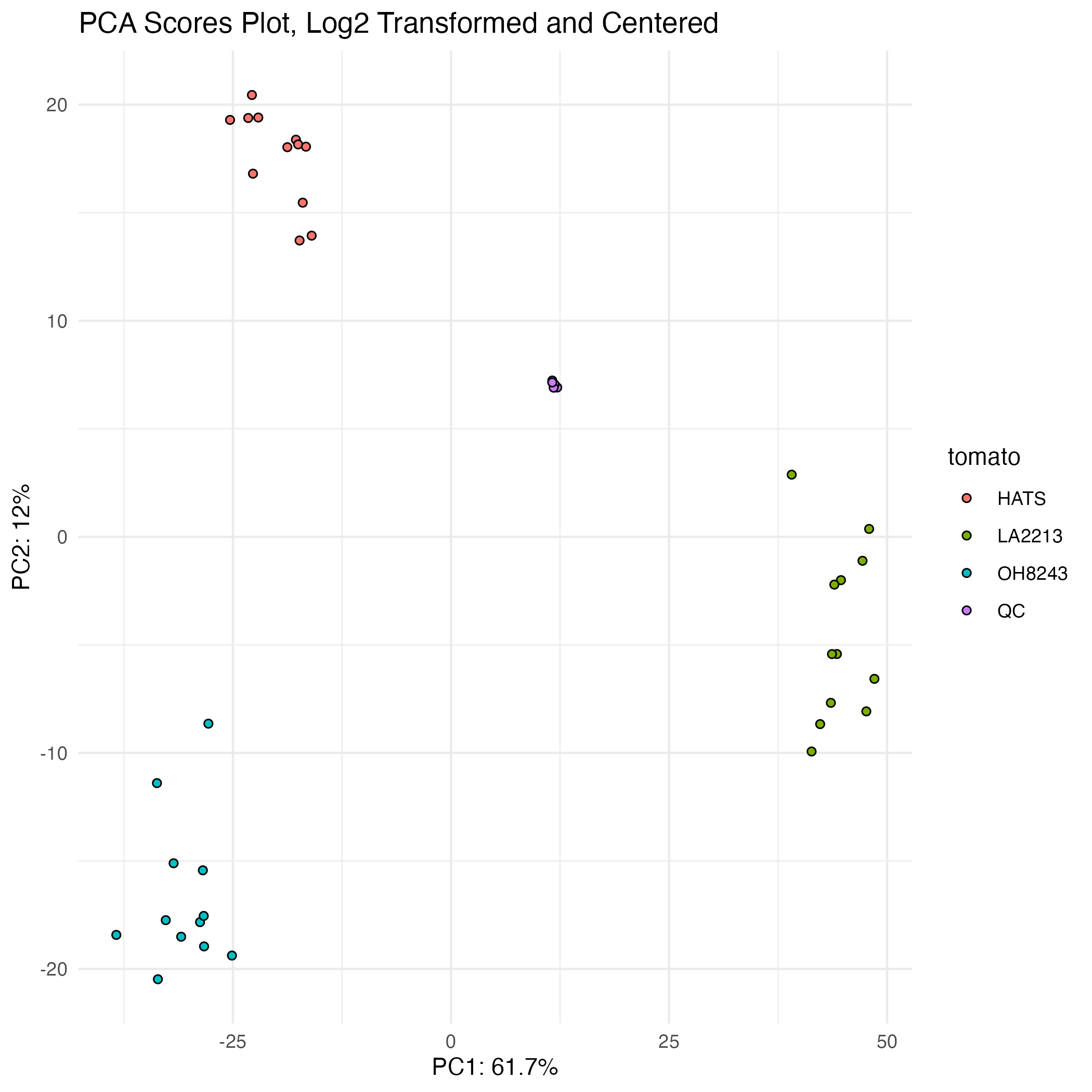
- Centering converts all relative intensities to be centered around zero instead of around mean concentrations
- This is particularly useful in metabolomics given that more intense features are not necessarily more abundant
- I like to center when conducting principal components analysis (PCA, more on this later)
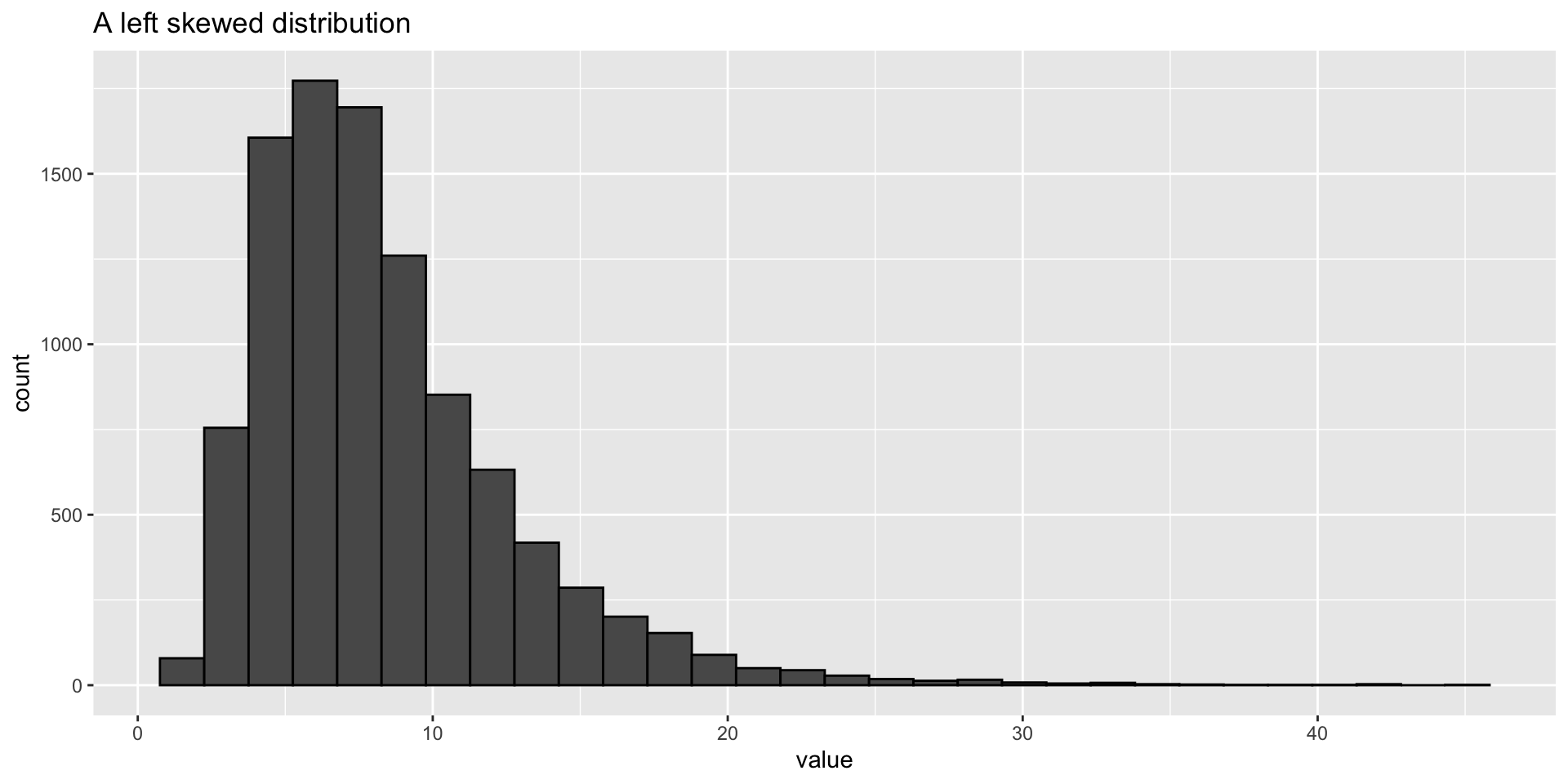
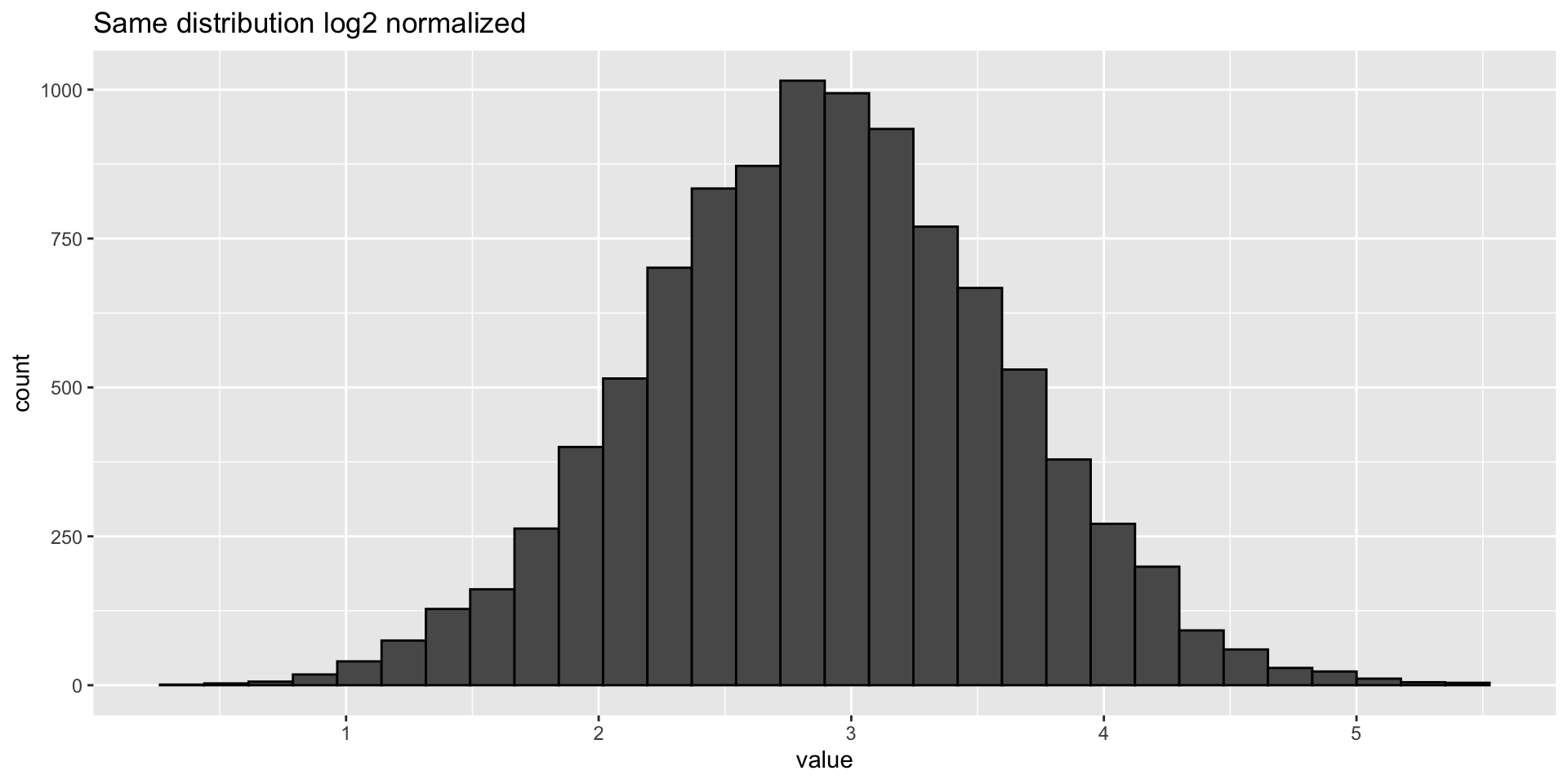
Log transformation - plots
- Log transforming can make your data look more normally distributed
Overlay your BPCs
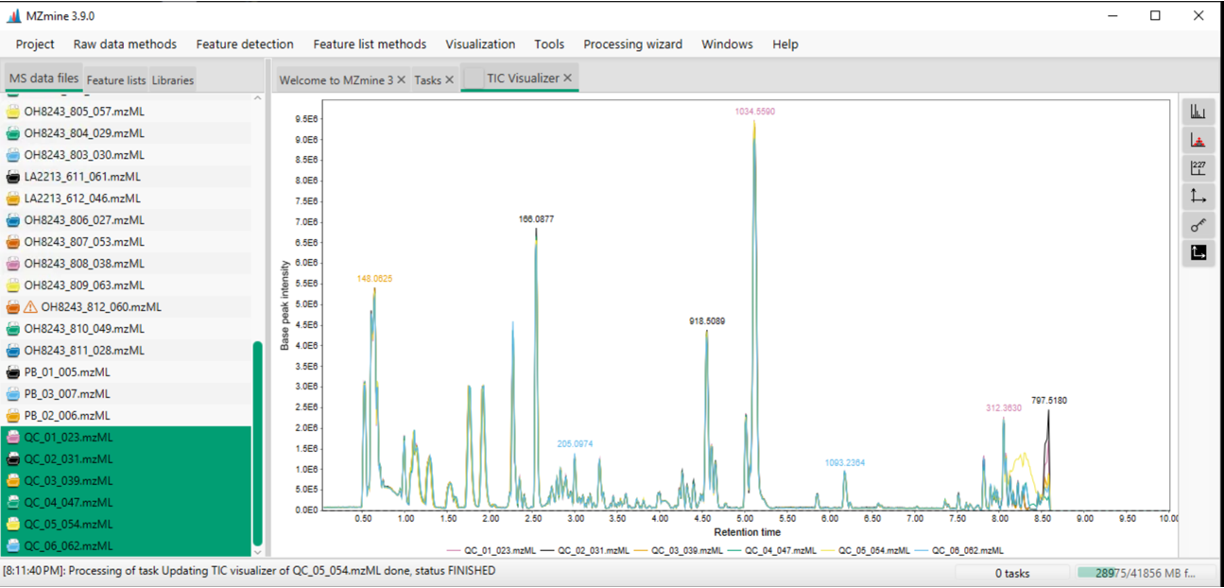
Overlaid base peak chromatograms in MZmine
Zoom in and look at your BPCs carefully
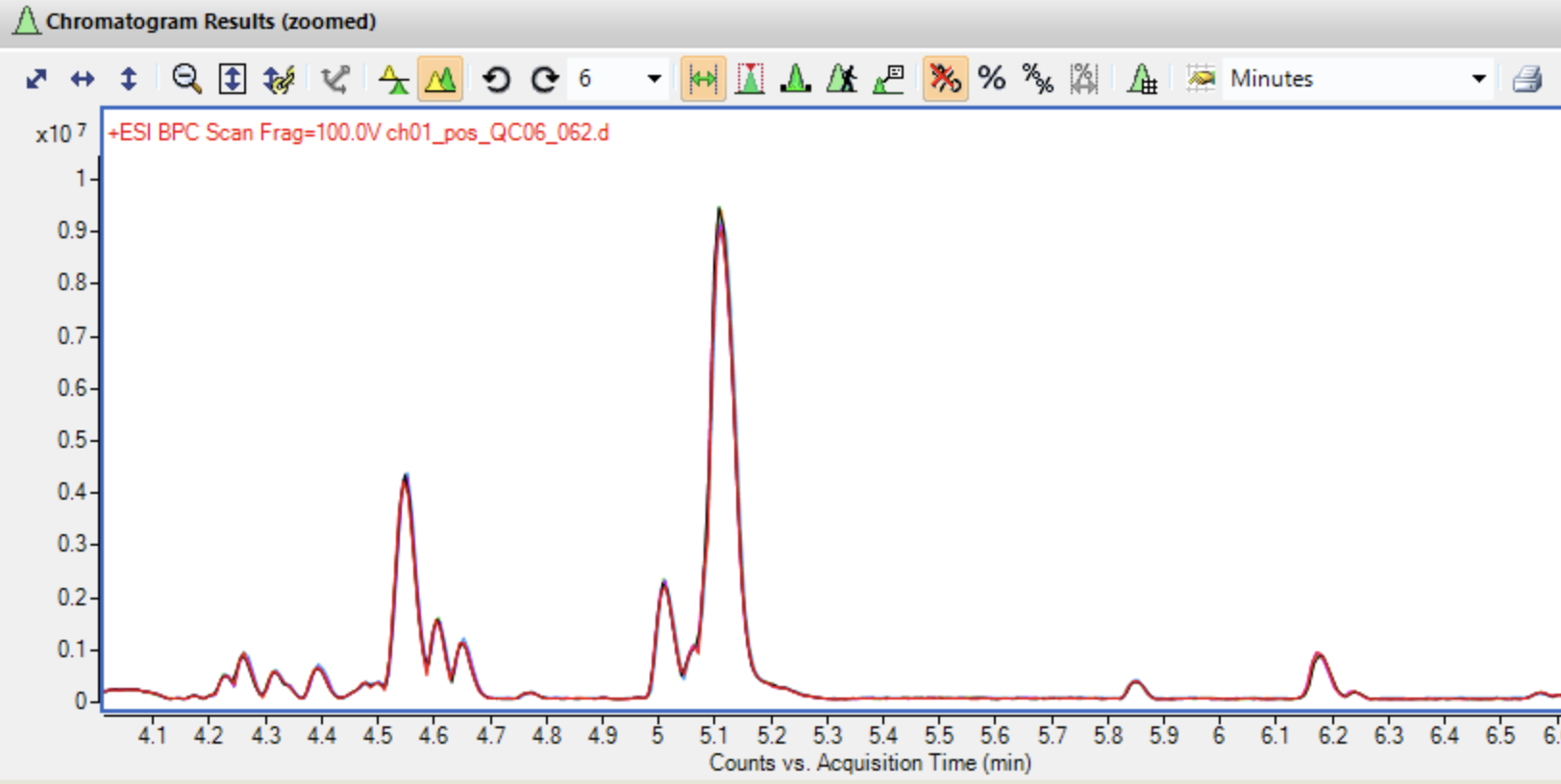
Overlaid base peak chromatograms in MassHunter
Look at a single feature for retention time shifting
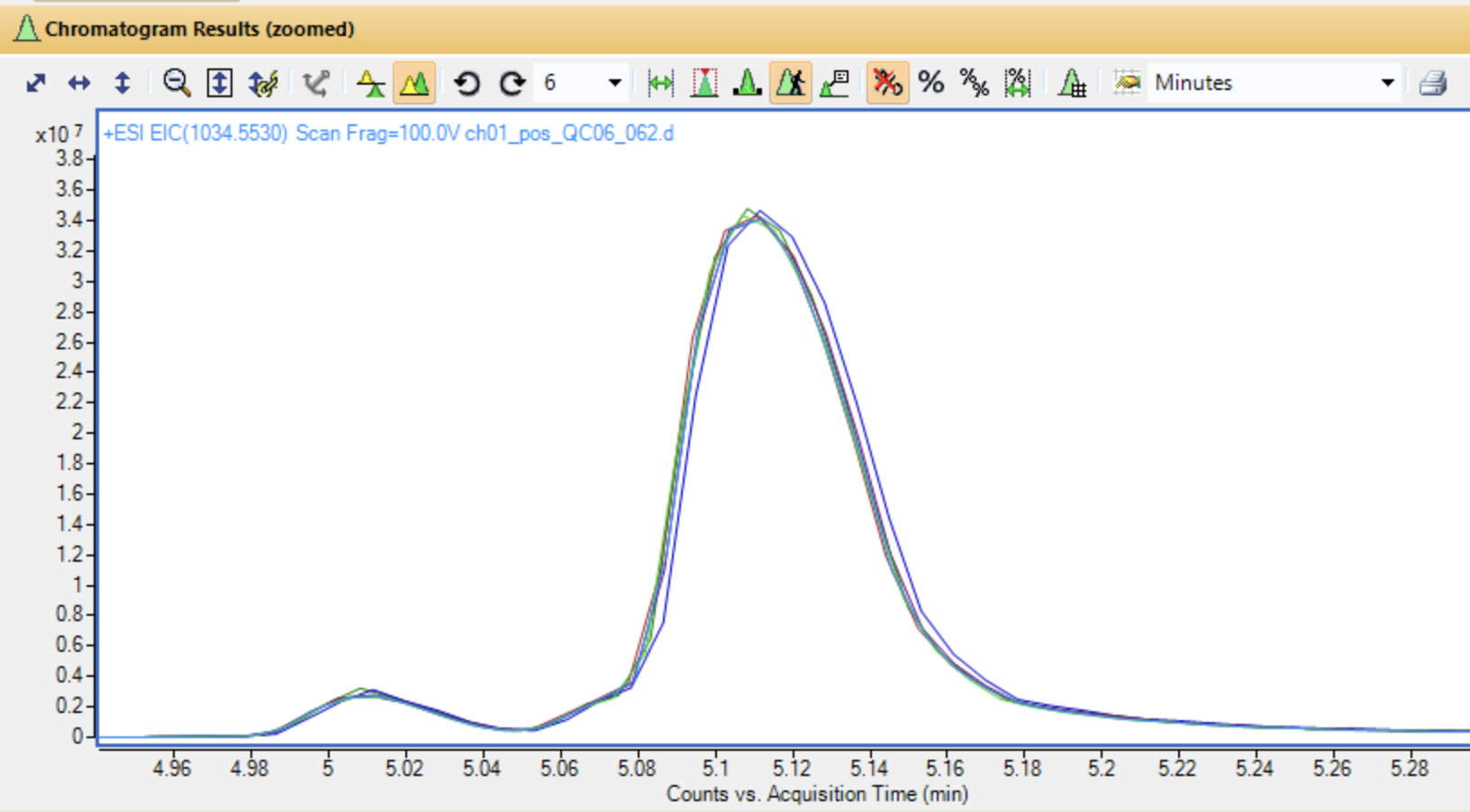
Overlaid extracted ion chromatograms in MassHunter
Create boxplots of features by sample
Ordering by sample groups 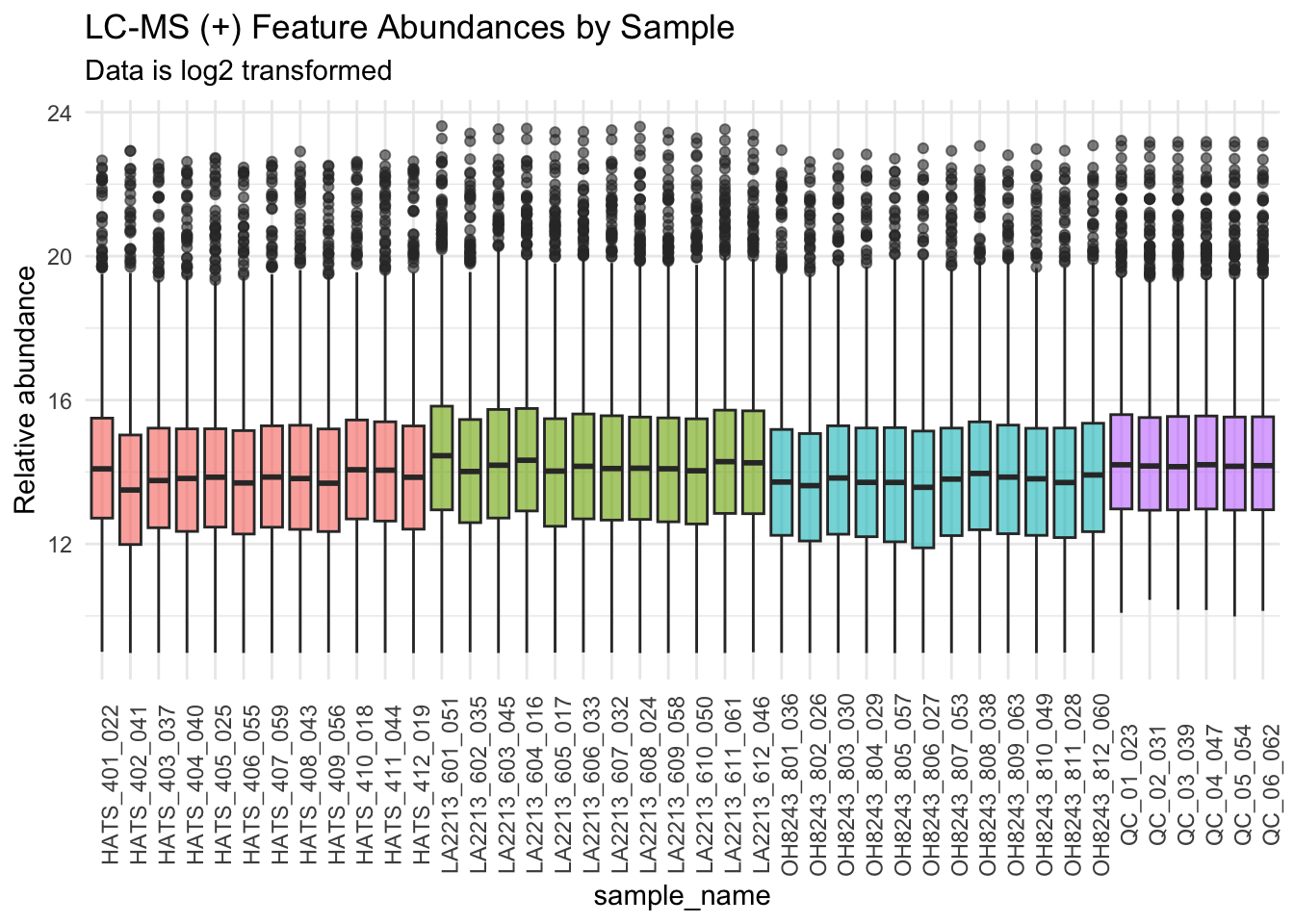
Ordering by run order 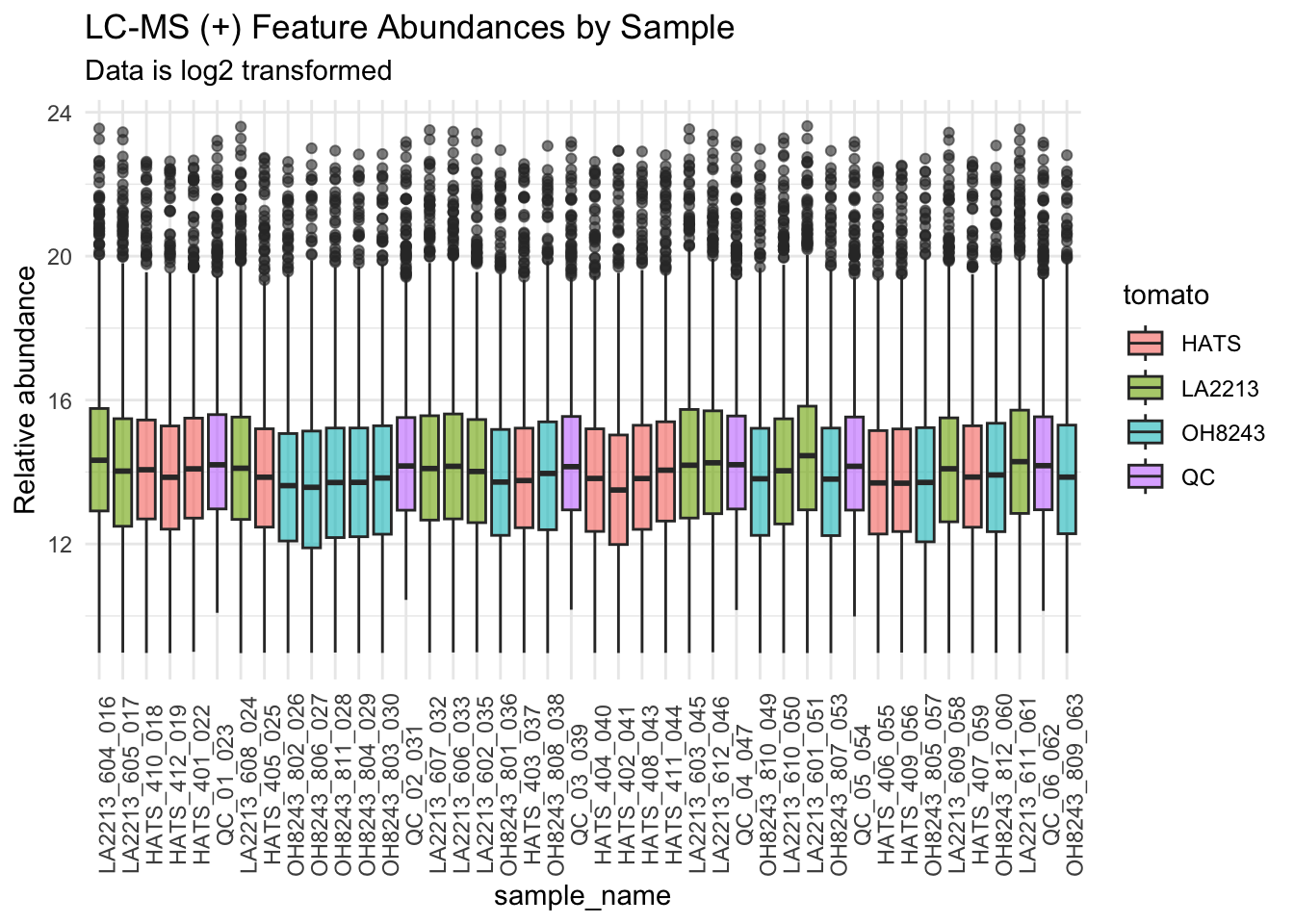
Your QCs should cluster in a PCA
A PCA where the QCs cluster beautifully
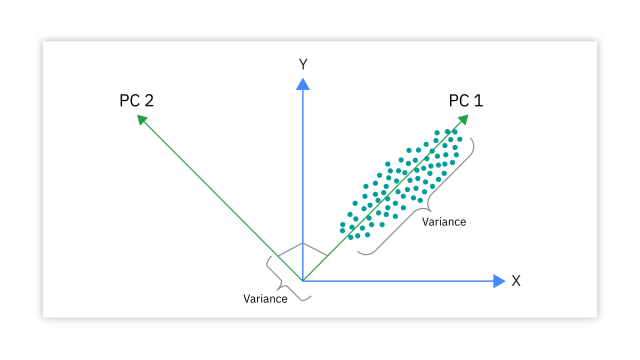
Unsupervised: Principal Components Analysis (PCA)
- A dimensionality reduction approach that transforms our data into a new system where principal coordinates (PCs) are drawn maximizing variation in our data.
- Each new PC is orthogonal to the previous one.
- Can interpret points closer together as more similar that those further apart
- The loadings plot helps us understand which features are most influential for each PC
Interpreting PCAs
PCA A) scores and B) loadings (from Dzakovich et al., 2022)
HCA applied to metabolomics
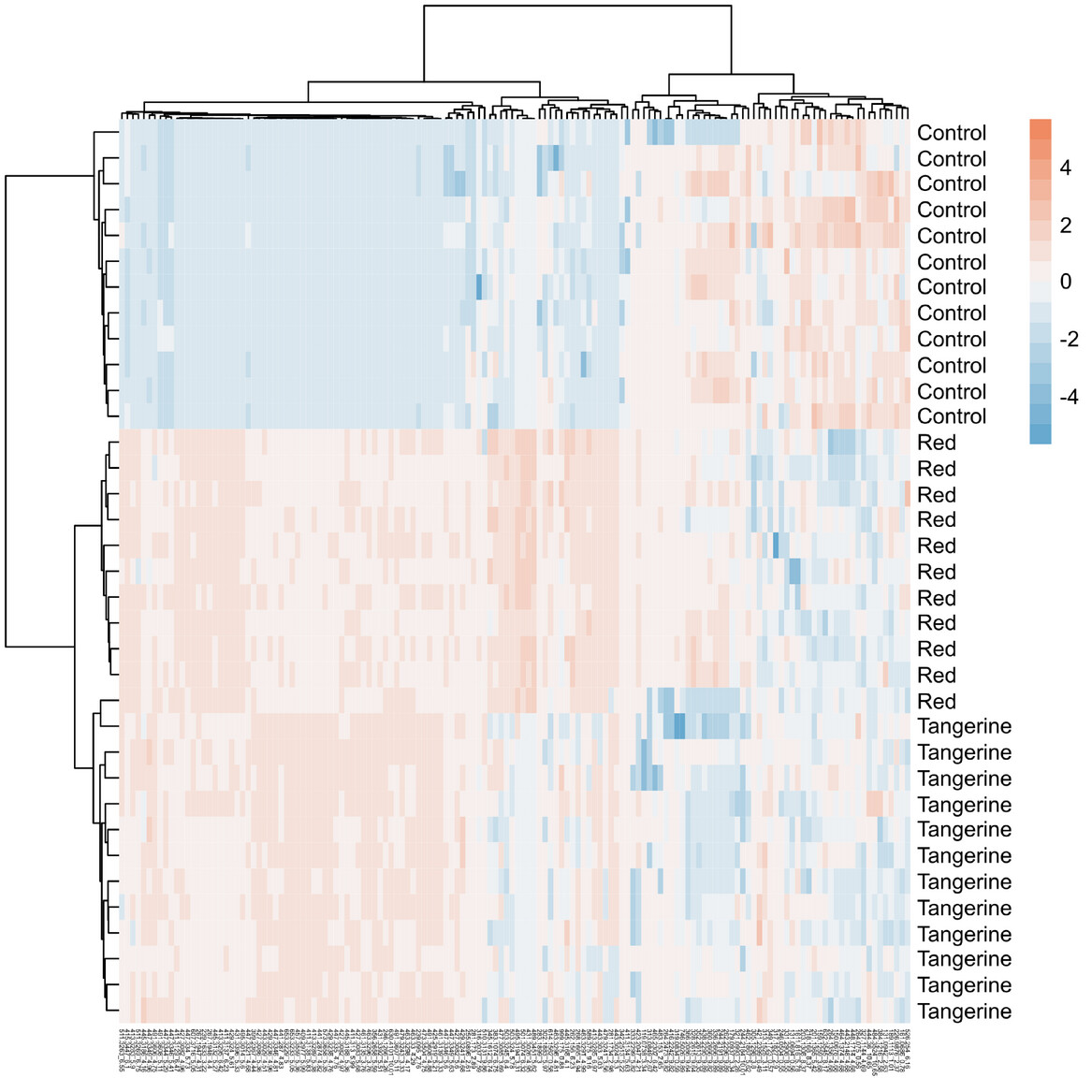
A hierarchical clustering example from Dzakovich et al., 2024
Unsupervised: K-means clustering
- Randomly assigns all samples to be a part of \(k\) clusters
- Calculates centroids and assigns samples to the nearest one
- Iterates until centroids stability or reach some maximum
- Can figure out number of clusters using a scree plot to visualize within cluster sums
- StatQuest explains K-means clustering

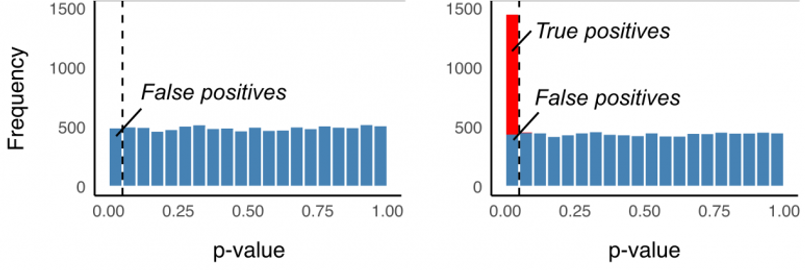
Ways to control for multiple testing
- Bonferroni correction: \(α/number\,of\,comparisons\) (very conservative, leads to false negatives)
- Benjamini Hochberg false discovery rate correction: adjust overall error rate to be α (tries to balance false negatives and positives)
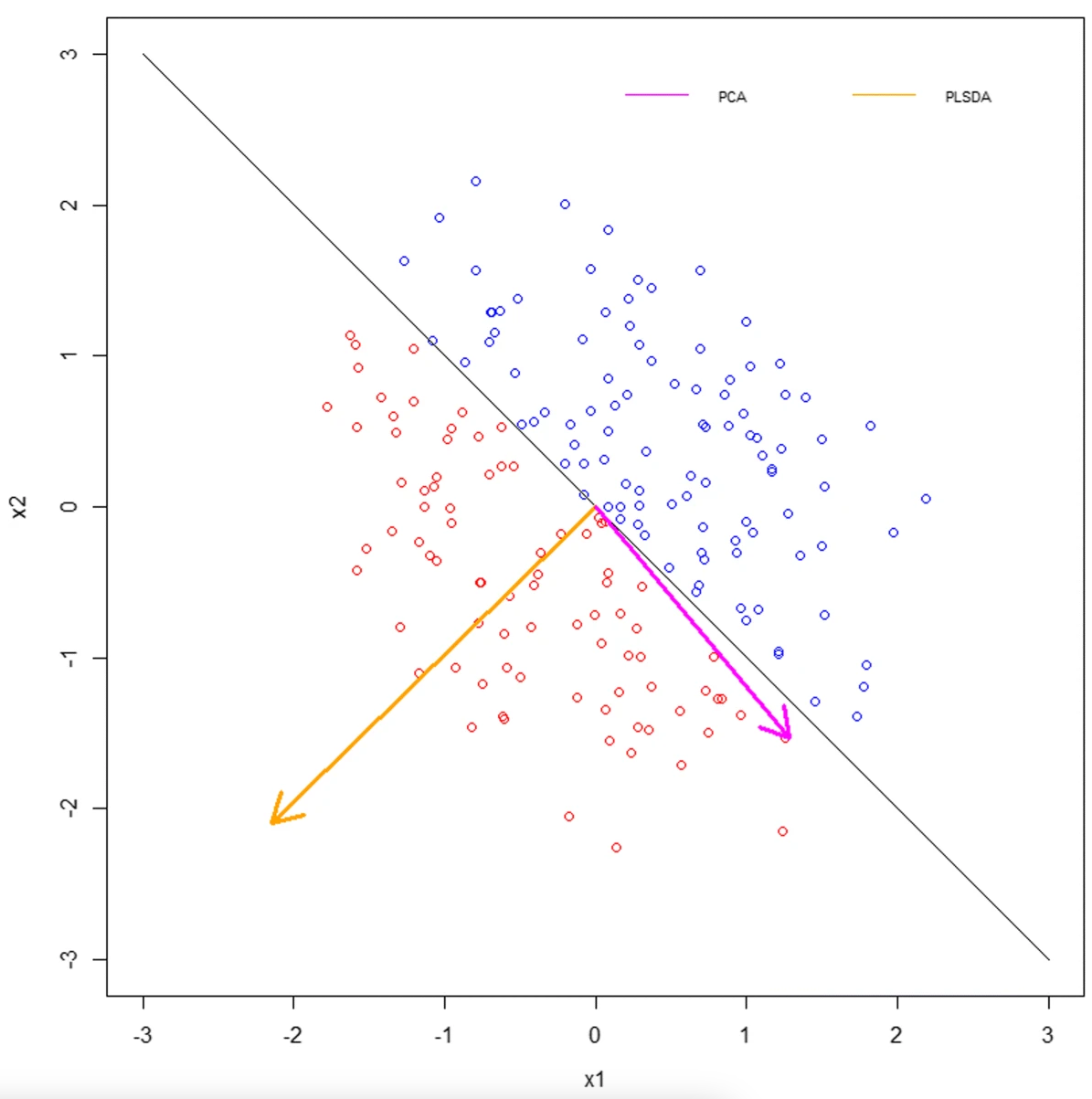
Supervised: PLS-DA
- Partial least squares discriminate analysis (PLS-DA) approaches optimize separation between groups
- Two data matrices, X: contains your features, Y: contains group identity
- Be sure to look at R^2 and Q^2 for both training and test sets
- Has a tendency to overfit
- Learn more about PLS-DA: Brereton and Lloyd, J Chemometrics 2014, Ruiz-Perez et al., BMC Bioinformatics 2020, Worley and Powers, Curr Metabolomics 2013.
Random forest
- A machine learning method for classification via construction of decision trees
- Trees are created with a random subset of variables
- Increase to 100% purity at the base of the tree
- Do this over and over
- A set (~1/3rd) is left out of the sample for each tree - this is the “out of bag (oob)” data, and can be used to see how accurate your classification is
- Learn more by watching this StatQuest video

Artificial neural networks
- Conceptually like a network of connected neurons, where each connection is weighted and a function transforms the sums to form the output
- Input data is mapped to latent structures, which are then mapped to output data
- Sometimes can be a “black box”
- Learn more by watching this StatQuest video

Others